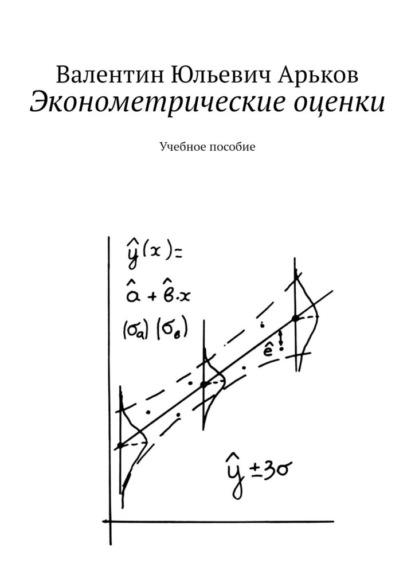
Рис. Результаты моделирования
Как можно видеть, и в этом примере оценка вероятности приблизительно соответствует точному, теоретическому значению 0,5.
Libre Office Calc – функция
Проведём ещё один эксперимент – по примеру того, что мы проделали в Excel с вызовом функции RAND, см. рис.
Рис. План демонстрации
Вводим функцию RAND в ячейку А2.
Затем вызываем заполнение диапазона нашей формулой: Sheet – Fill Cells – Fill Down, см. рис.
Рис. Заполнение ячеек
Рис. Результаты моделирования
Как видим, мы можем заполнять ячейки почти так же, как мы это проделали в Excel. Названия функций тоже совпадают. Во многом это объясняется тем, что пользователи ожидают совместимость на уровне файлов. А в файлах могут быть не только числа, но и вызовы функций. В нашем примере это функции RAND, ROUND и AVERAGE.
В результате мы тоже получили оценку вероятности около 0,5. И тоже с небольшой погрешностью. И эта случайность тоже заметна при многократном повторении опыта.
Когда мы вызываем генератор через функцию, электронная таблица пересчитывает все значения при любых изменениях, при обновлении таблицы и при сохранении файла. Все оценки будут вокруг теоретического значения 0,5, но все будут немного разными – плюс-минус.
Вам предстоит проделать показанные эксперименты. Повторите этот опыт несколько раз, чтобы убедиться, что оценка вероятности немного меняется. Но в среднем оценка «крутится» вокруг точного значения, см. рис.
Рис. План задания
Jupyter Lab
Следующий эксперимент мы проделаем в питоне. Или в Python – если больше нравятся английские названия.
Здесь мы с вами познакомимся с некоторыми приемами работы в диалоговой среде Anaconda / Jupyter Lab и некоторыми командами Python.
Рис. Программа в Jupyter Lab
В первой строчке мы импортируем библиотеку numpy и назначаем ей псевдоним np – для краткости. Это библиотека для работы с числовыми массивами. В обычном, базовом питоне мы тоже можем создавать различные объекты. Однако, numpy позволяет работать с матрицами, то есть с массивами / таблицами чисел. Это могут быть столбцы, или строки, или таблички чисел. Все они условно называются массивами.
Дальше мы будем обращаться к функциям из этой библиотеки np.
Вторая строка – вызов генератора случайных чисел с равномерным распределением. В аргументах функции rand указываем размеры массива, который хотим получить: 10000 строк и 1 столбец.
Следующим шагом мы округляем эти числа с помощью функции round.
Далее находим среднее значение для всего этого массива чисел. Это делает функция mean. Полученную оценку вероятности выводим на экран.
Здесь надо отметить один любопытный момент. Функции для вычисления среднего значения могут называться MEAN и AVERAGE.